如何将PDF文件中的文字提取出来
作为一个办公室文员,经常需要从网上下载一些资料,摘取整理其中的文字,可是从网上下载的资料,好多是图片型PDF(即该PDF文档中所有文字都是扫描的图片素材)或图片文件,那如何才能将这类文件中的文字提取出来?这个问题相信在日常的工作中会有不少机会遇到,小编在这里介绍捷速PDF文字识别软件,可以轻松的将PDF文件中的文字提取出来。
PDF文件中的文字提取方法
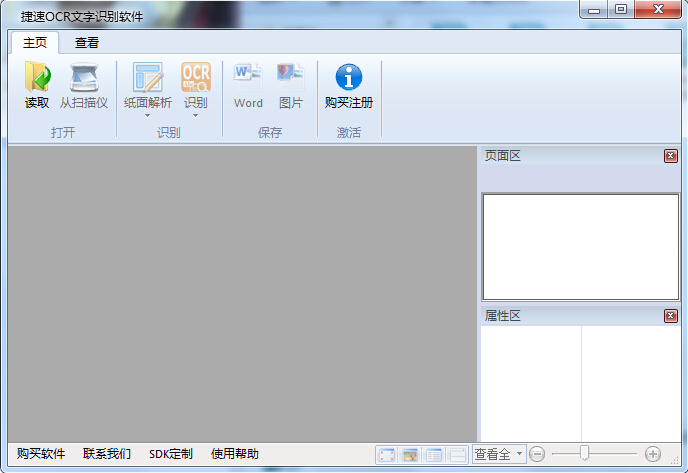
首先,打开下载好捷速PDF文字识别软件,打开软件就自动进入到操作主界面,界面非常的简洁,所有的操作键都在软件的左上方。首先我们点击第一个“读取”按钮,找到需要识别的文件所在位置,点击即可完成文件的添加工作。
然后,页面会出现原文件,这个时候我们点击“纸面解析”按钮,软件会对文件的段落等进行分析,这样识别得到的文件就会与原文件的段落排版一致。
再则,一切准备就绪,点击“识别”按钮,单页的文件瞬间就能完成识别工作。页面的右边就会出现识别的结果,根据原文进行核对。
最后,识别好的文件选择保存的格式,直接点击“word”或是“图片”即可。
将捷速PDF文字识别软件按照上述的方法可以将PDF转换成可编辑文字,在人们的笔记本电脑中,往往存储着大量PDF文档,经常要把其中的一些文字或图片转移到Word中进行编辑,这是很多人的困扰。PDF阅读器无法直接复制图片和文字,这就需要借用捷速PDF文字识别软件。望小编的介绍方法能够对大家能够有所帮助。》》》》推荐阅读:
pdf文字编辑软件有吗



 捷速OCR文字识别软件是一款具备较高识别率的图像文字识别软件,拥有批量处理和高速识别功能;软件支持多国语言识别,支持多种文件格式如:JPG、GIF、PNG、BMP、TIF、PDF文件和扫描件。
捷速OCR文字识别软件是一款具备较高识别率的图像文字识别软件,拥有批量处理和高速识别功能;软件支持多国语言识别,支持多种文件格式如:JPG、GIF、PNG、BMP、TIF、PDF文件和扫描件。
 181-2107-4602
181-2107-4602


